Machine Learning for MINERvA Physics Reconstruction
Tomasz Golan
IFT seminar, 05.01.2018
Outline
Motivation
(for MINERvA experiment)
Neutrino oscillations
- three neutrino flavors: electron, muon, tau
- created in one of the flavors can be detected with a different flavor later
- The Nobel Price in Physics 2015: Takaaki Kajita and Arthur B. McDonald (Super-K, SNO)
 src: nobelprize.org
src: nobelprize.org
Oscillation experiment
MINERvA
Main INjector ExpeRiment \(\nu\)-A
MINERvA Experiment
- MINERvA is a neutrino-scattering experiment at Fermilab
- Collaboration of about 50-100 physicist
- NuMI beam is used to measure cross section for neutrino-nucleus interactions
- The detector includes several different nuclear targets

NuMI Beamline
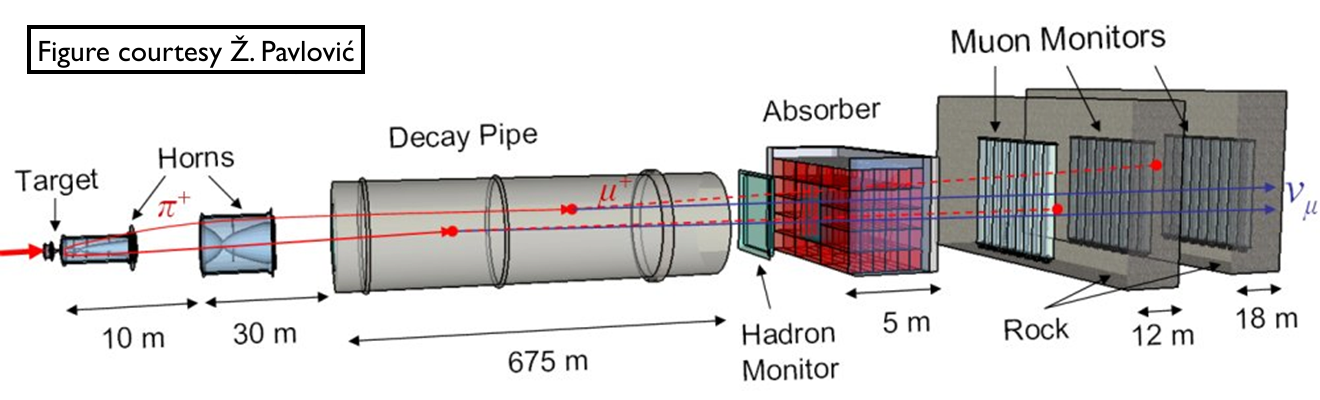
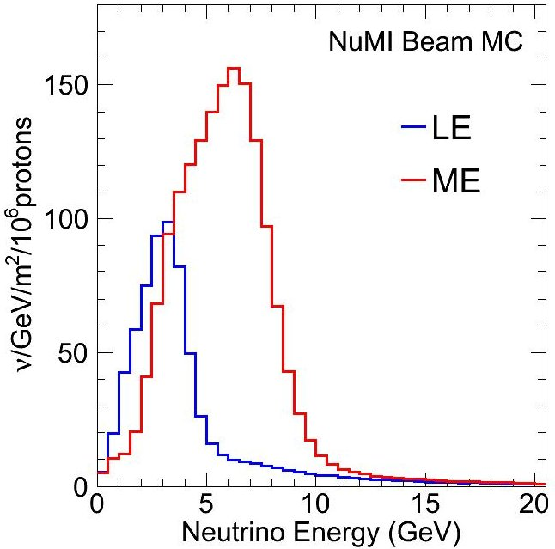
Low vs Medium Energy
by changing distance between horns one can change energy spectrum
by changing horns polarization one can switch between neutrino and anti-neutrino mode
LE vs ME analyses
- LE analyses: almost done
- ME analyses: starting now
- more energy
- more particles in the final state
- more messy events
- more problems with the reconstruction
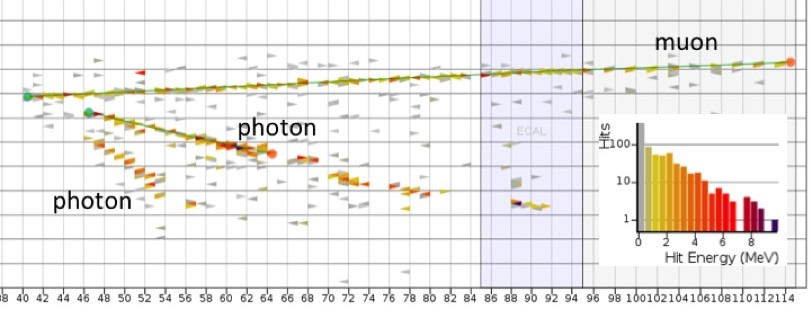
LE event example
MINERvA Detector
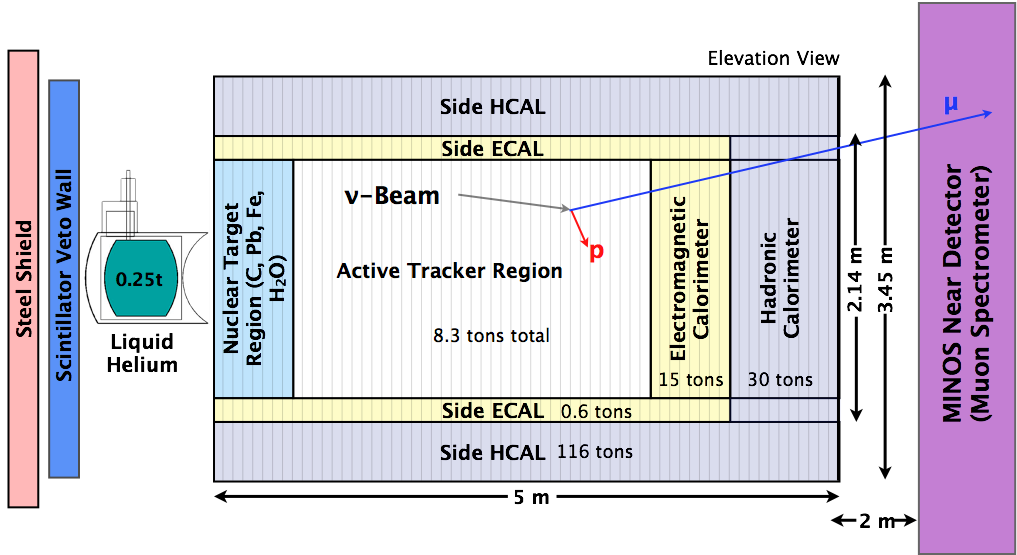
Nuclear targets
![]()
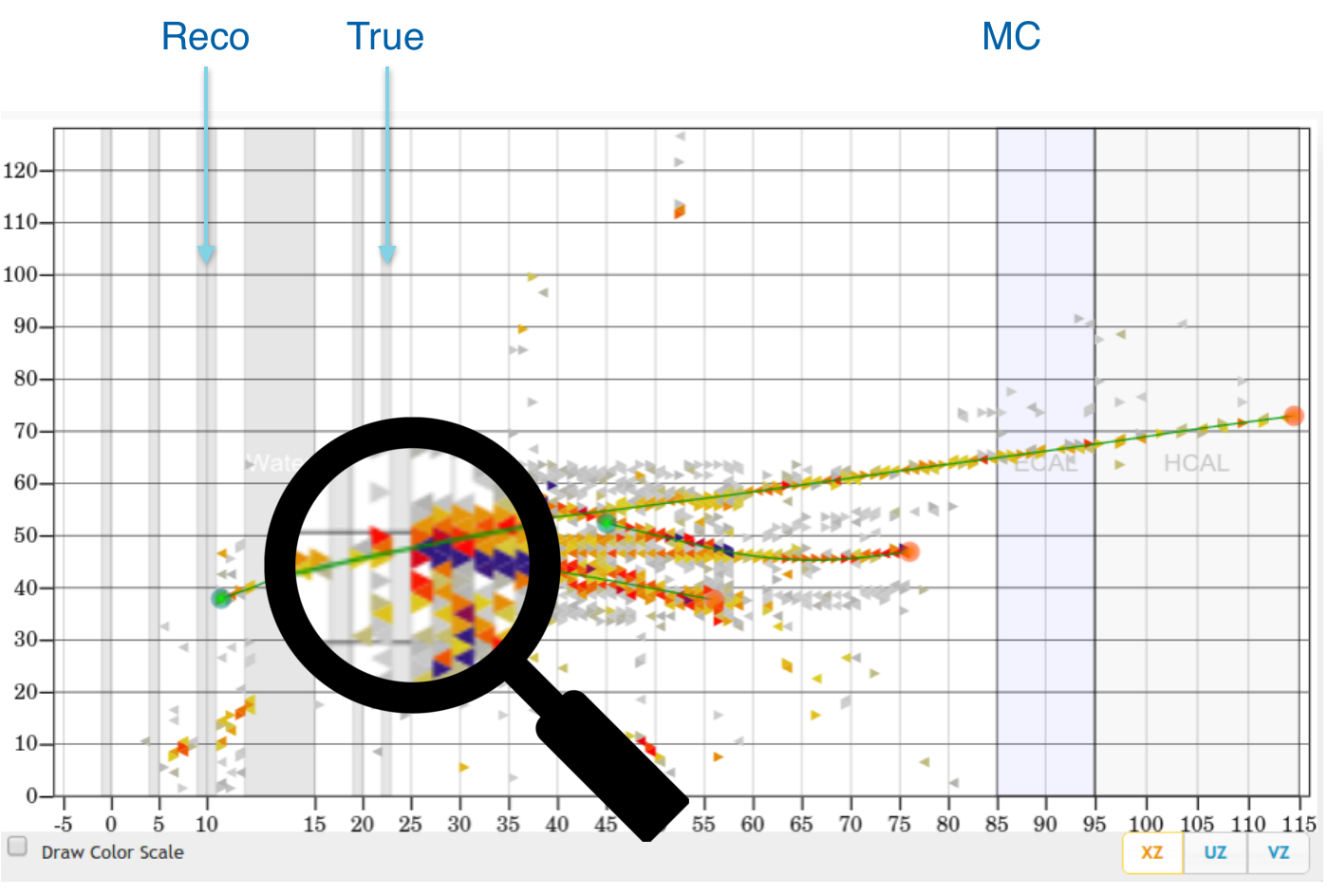
Event example 1
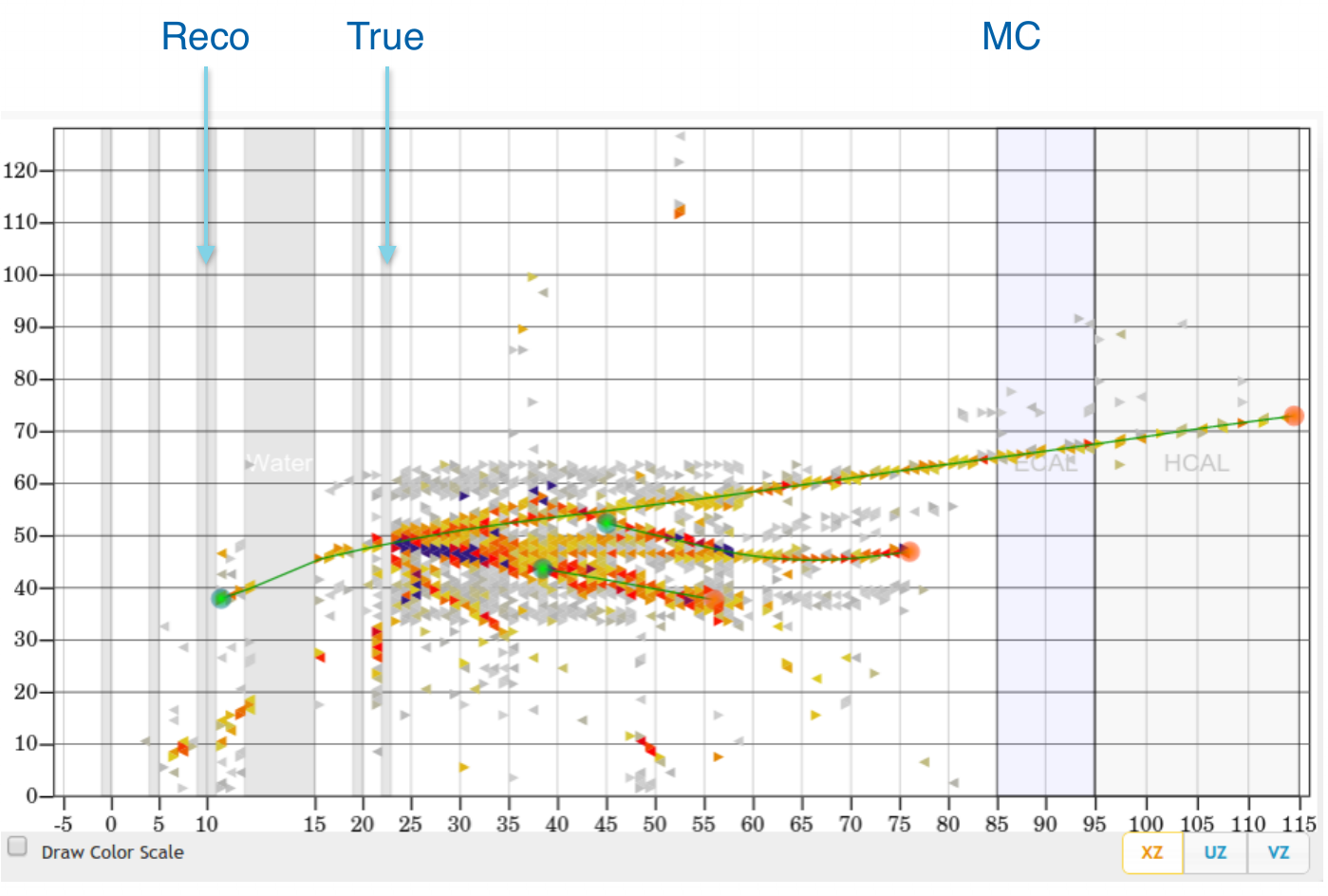
courtesy of G. Perdue
Event example 2
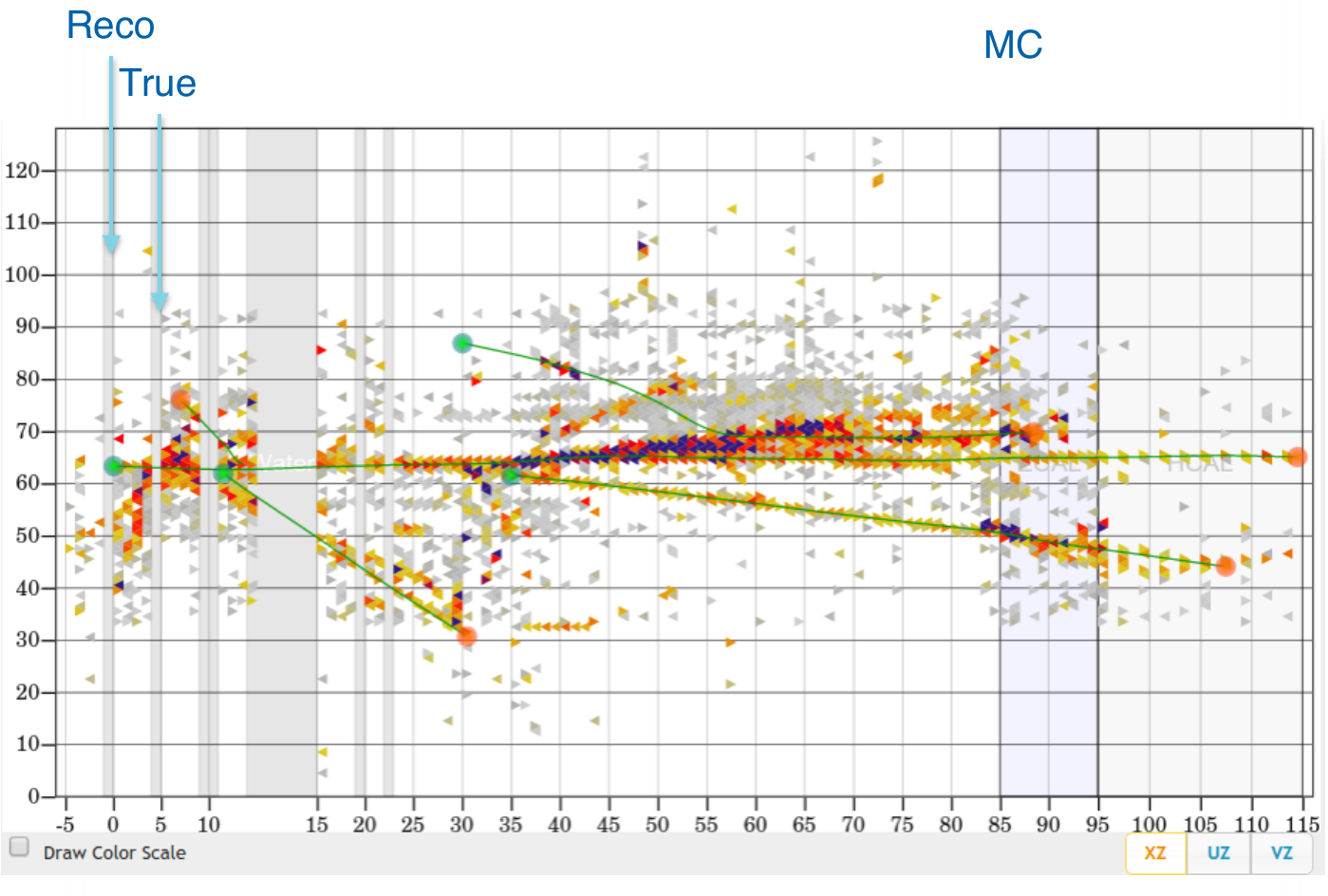
courtesy of G. Perdue
Vertex Reconstruction
tracking based algorithms fail for high energy events
"by eye" method is very often more accurate
idea: use algorithms for images analysis and pattern recognition
Machine Learning
Why ML?
ImageNet is an image database
- Annual competition for classification
- 2010: 71.8%
- 2011: 74.3%
- 2012: 84.0%
- 2013: 88.2%
- 2014: 93.3%
- 2015: 96.4%
- Humans: about 95%
- Why humans fail?

Siberian Husky or Alaskan Malamute?
Understanding CNN
If you can't explain it simply, you don't understand it well enough.
Albert Einstein
- lets start from linear regression
- then introduce a single neuron and neural networks
- to finally get to convolutional neural networks
Linear Regression
Notation
- Hypothesis (for convenience \(x_0 = 1\)): \[h(x) = w_0 + w_1x_1 + ... + w_nx_n = \sum\limits_{i=0}^n w_i x_i = w^T x\]
- Cost function: \[f(w) = \frac{1}{2}\sum\limits_{i=0}^n\left(h (x^{(i)}) - y^{(i)}\right)^2\]
- Learning step (gradient descent, \(\alpha\) - training rate): \[w_j = w_j - \alpha\frac{\partial f(w)}{\partial w_j} = w_j + \alpha\sum\limits_{i=0}^n\left(y^{(i)} - h (x^{(i)})\right)x_j\]
Example
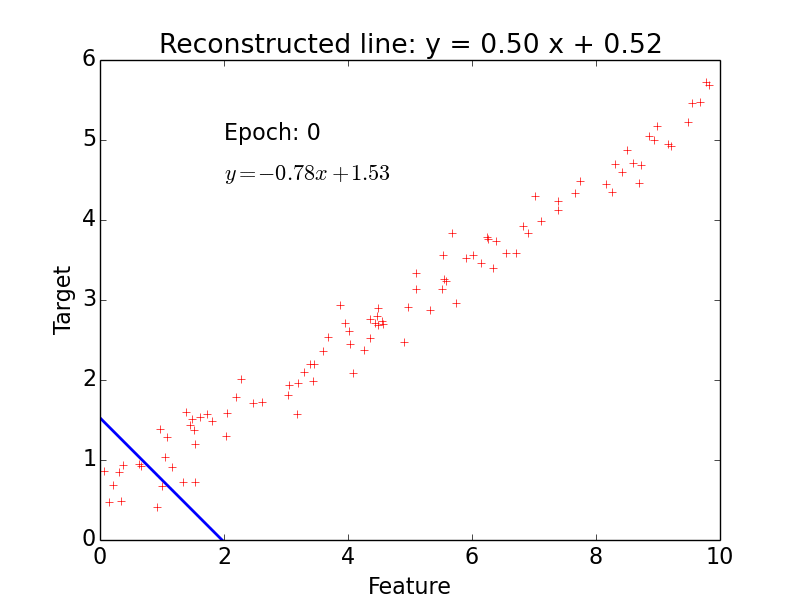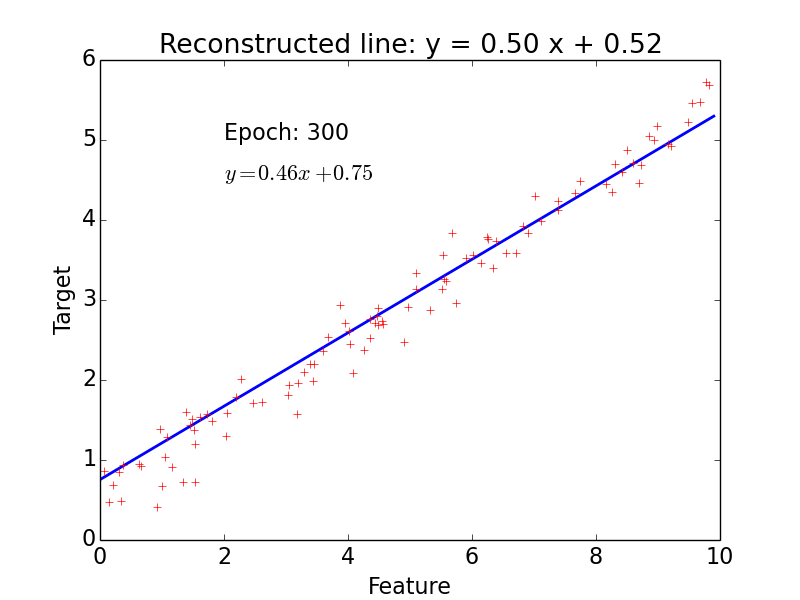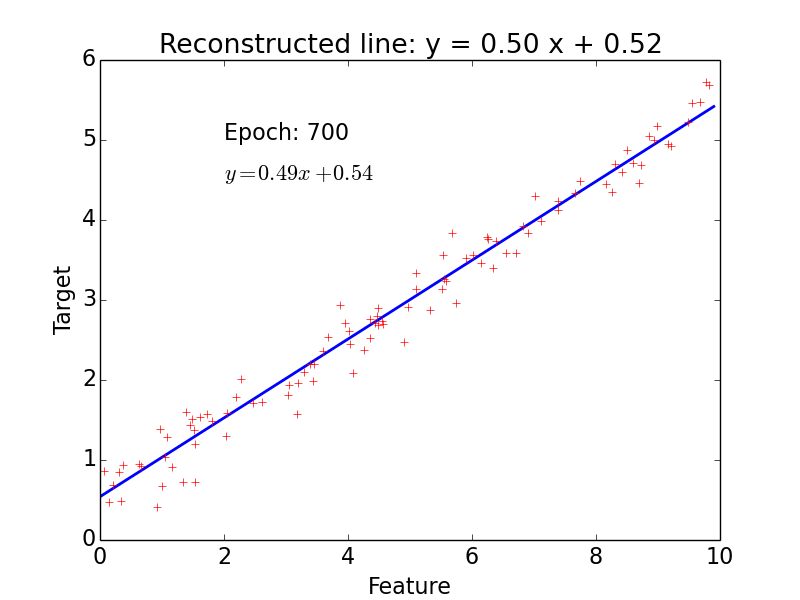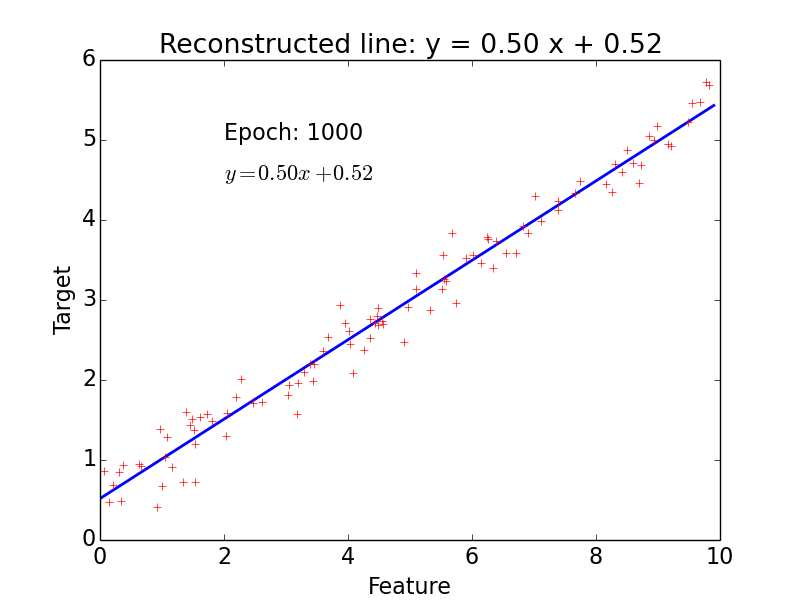
epoch = one loop over the whole training sample
for each feature vector weights are updated using gradient descent method
Classification
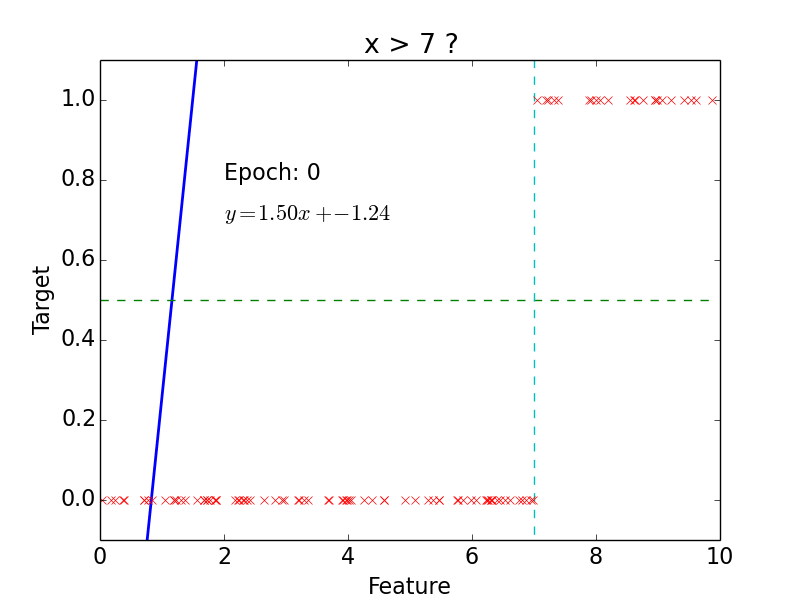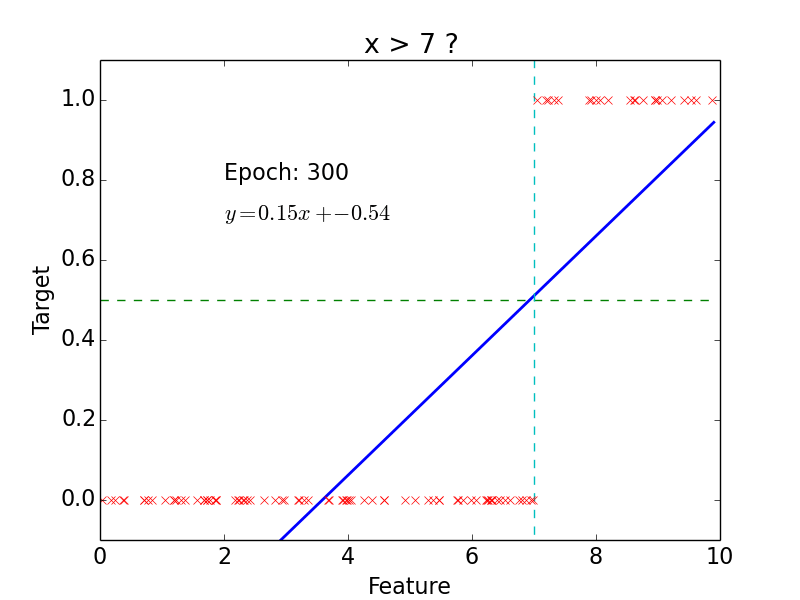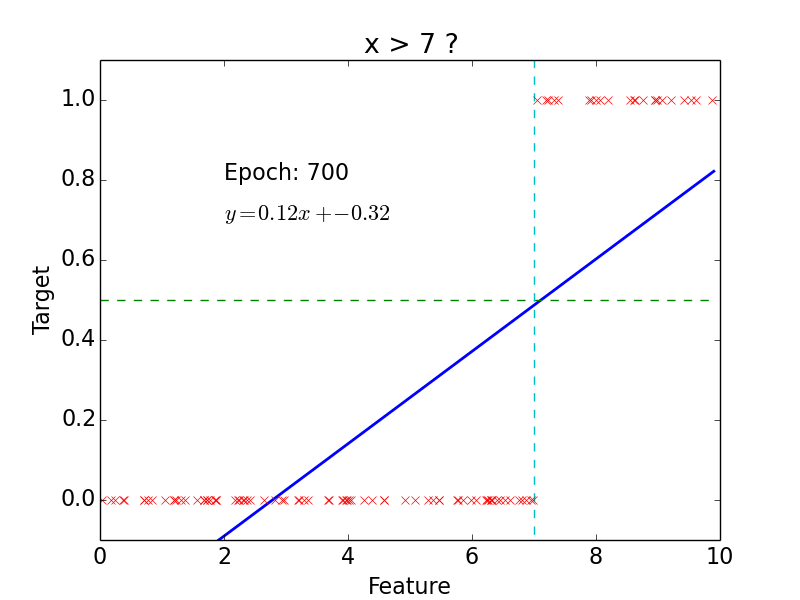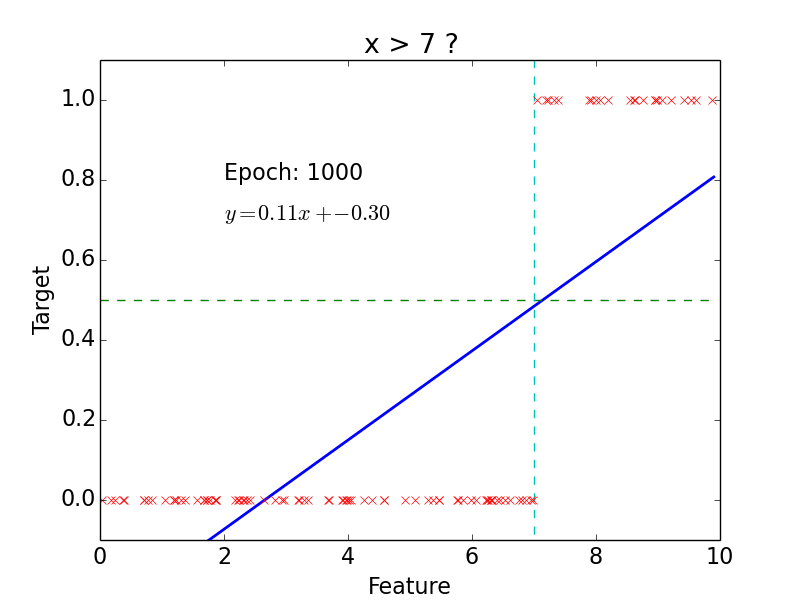
target: \(y = 0, 1\)
not really efficient for classification
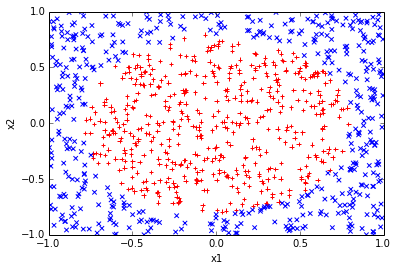
imagine having some data ~ 100
- logistic function does better job
Classification
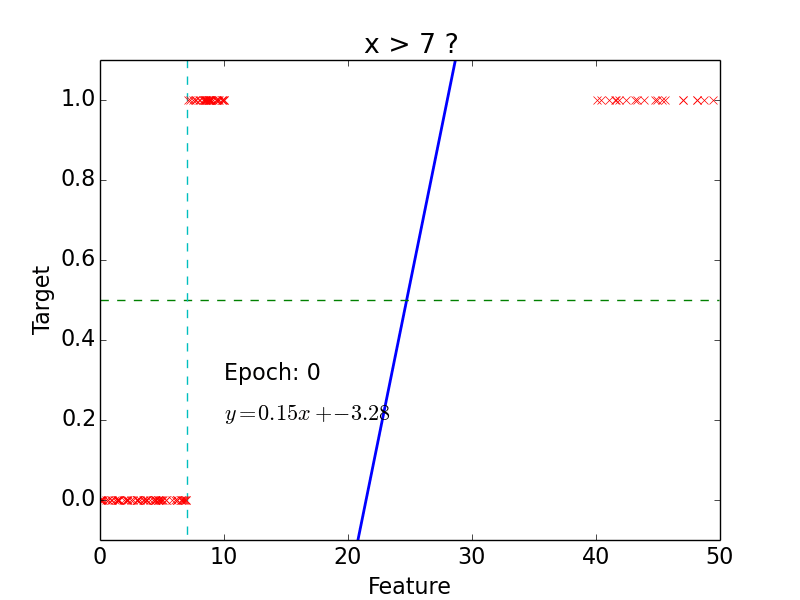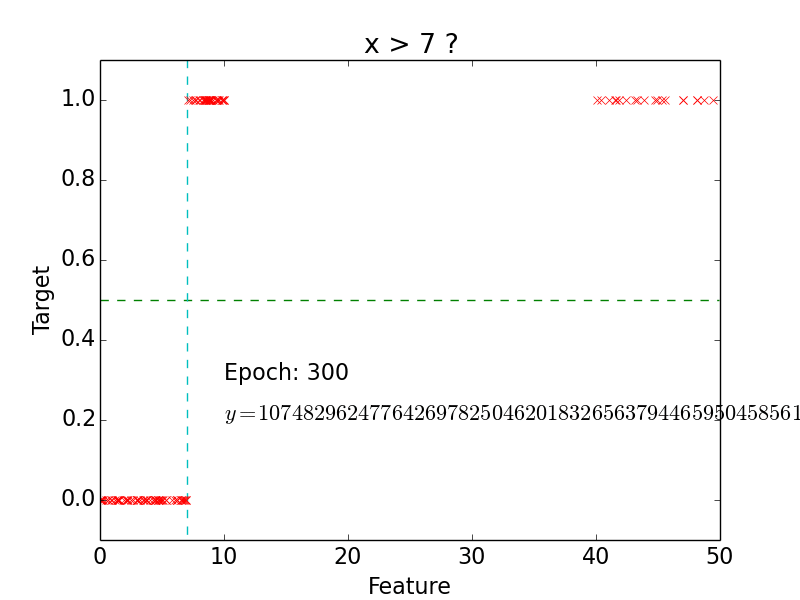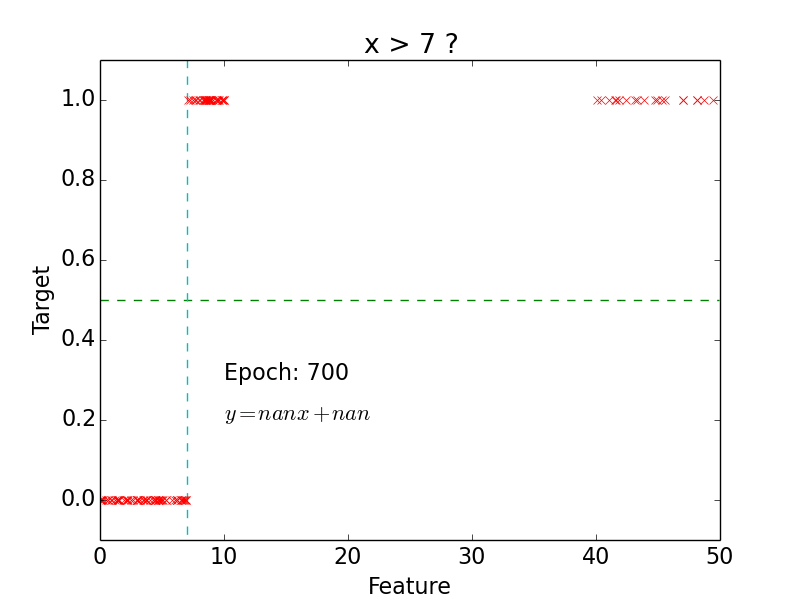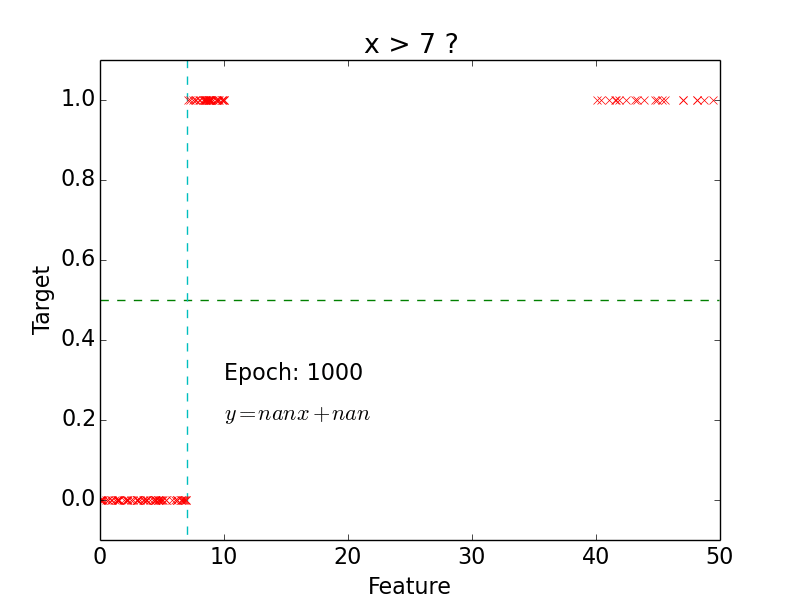
Logistic function
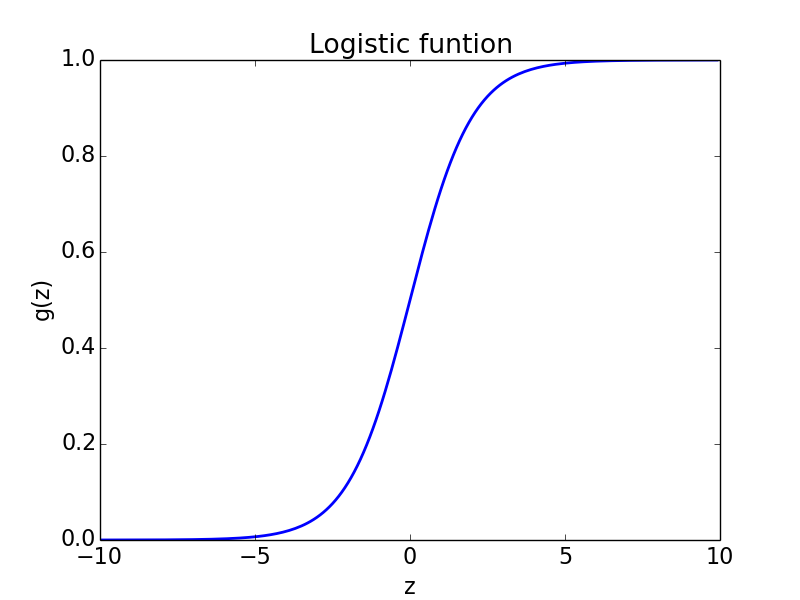
Logistic function: \[g(z) = \frac{1}{1 + e^{-z}}\]
- Hypothesis: \[h(x) = g(w^Tx) = \frac{1}{1 + e^{-w^Tx}}\]
Results
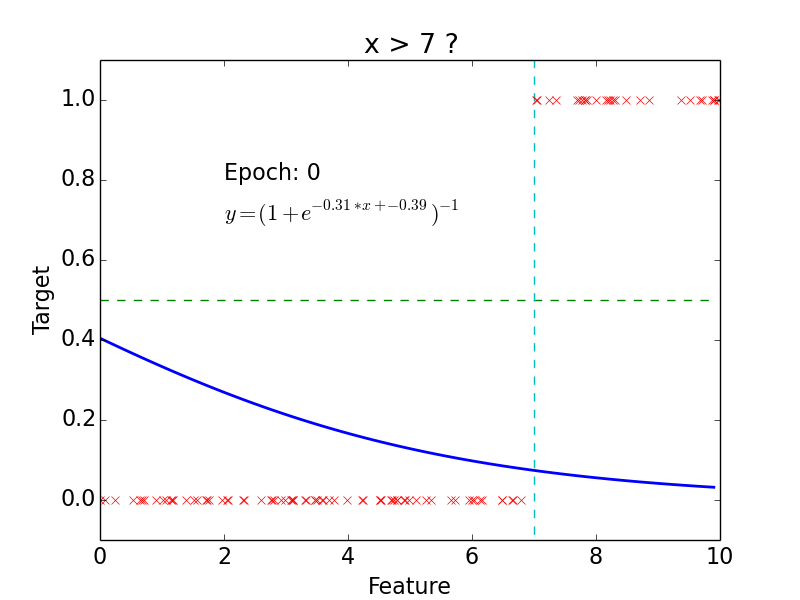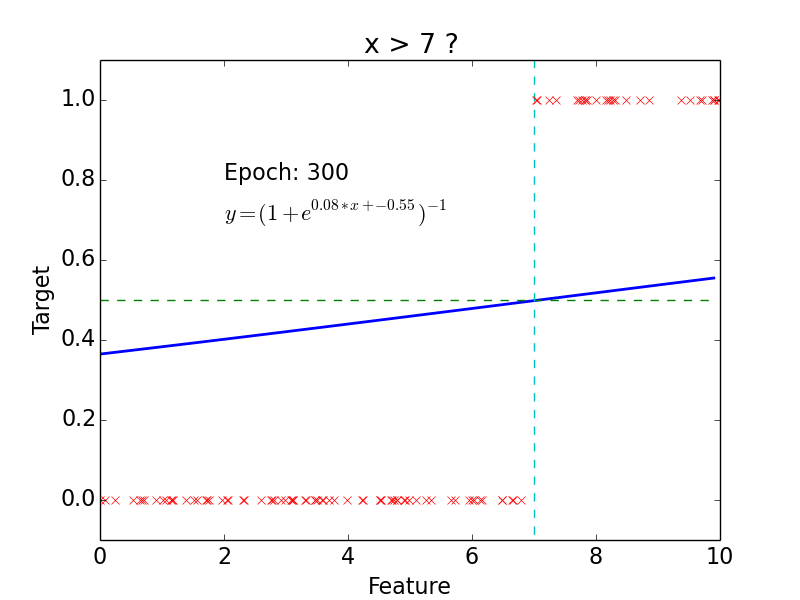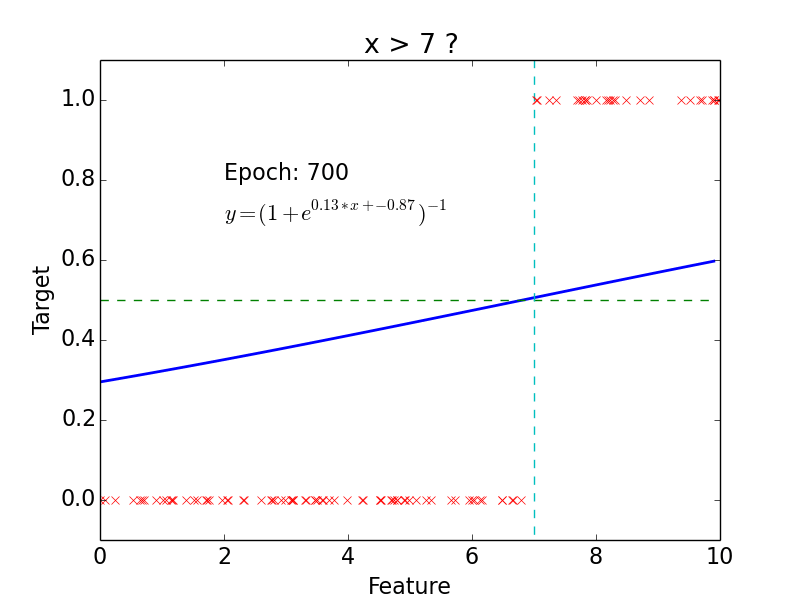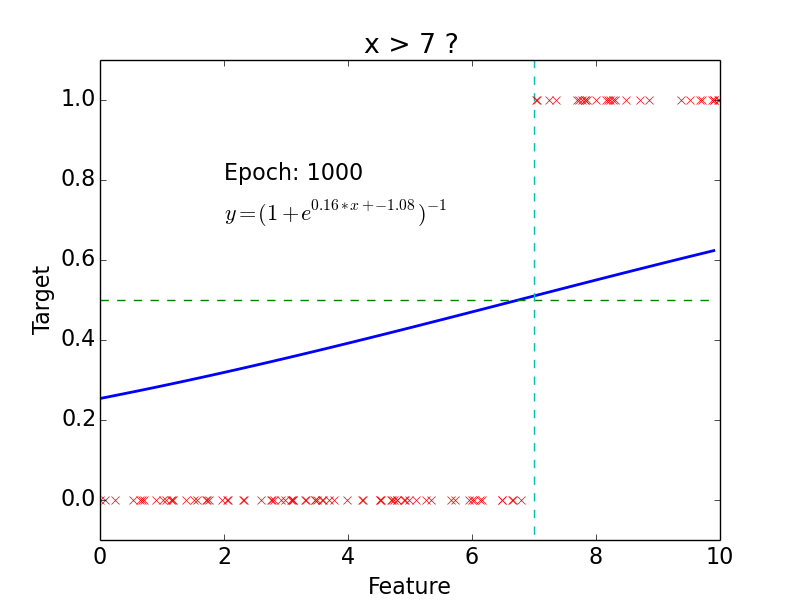
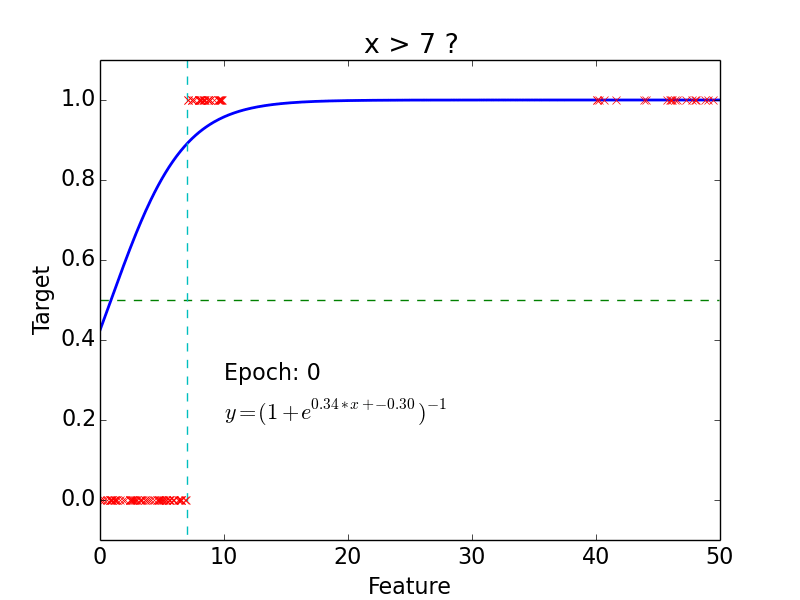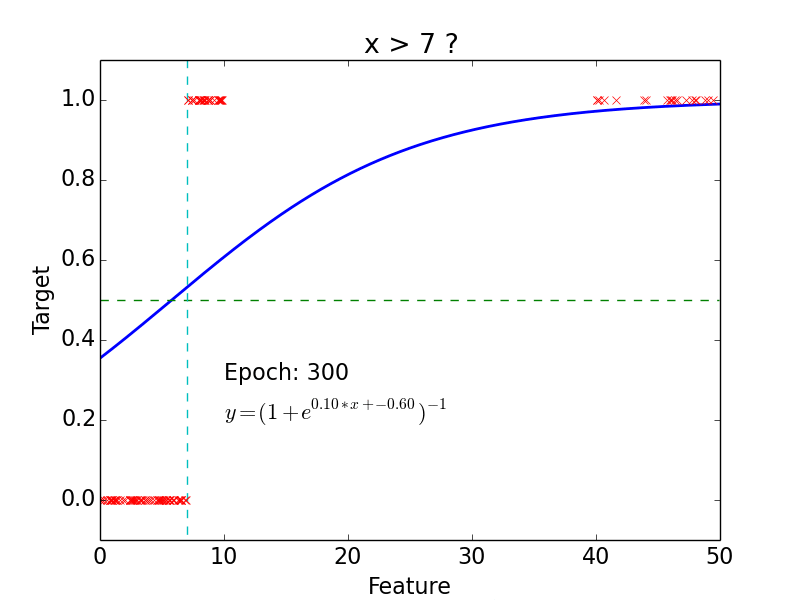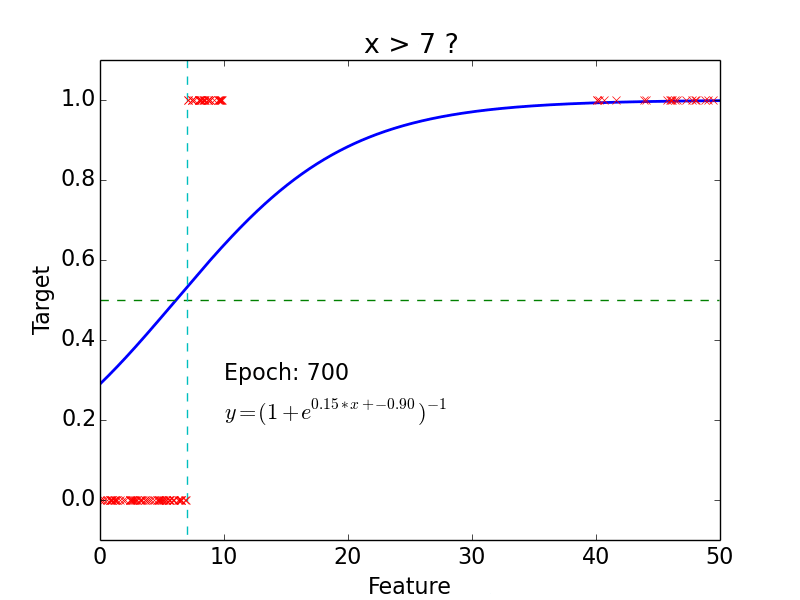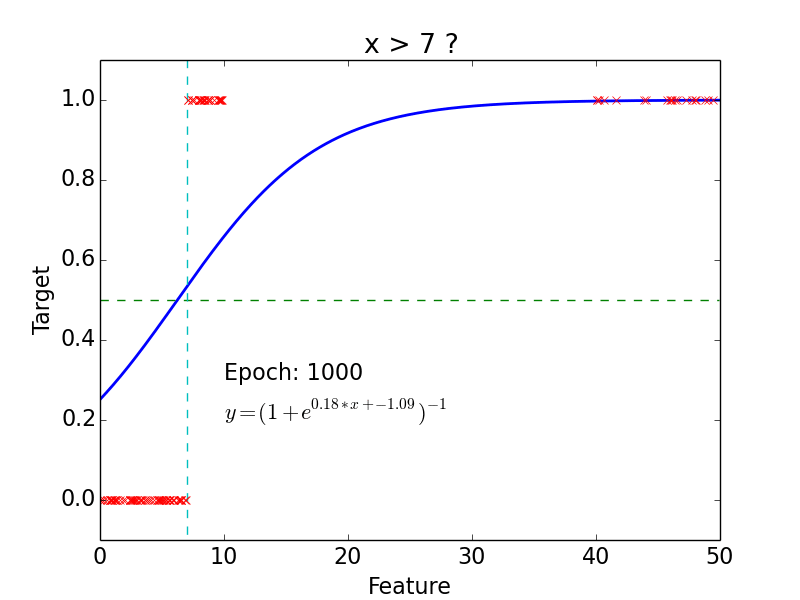
Why do we need neural networks?
We can do classification
We can do regression
But real problems are nonlinear
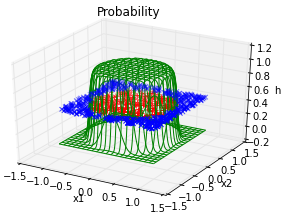
Trick
Feature vector: \[(x,y) \rightarrow (x,y,x^2,y^2)\]
Hypothesis: \[h (x) = \frac{1}{1 + e^{-w_0 - w_1x - w_2y - w_3x^2 - w_4y^2}}\]
In general, adding extra dimension by hand would be hard / impossible. Neural networks do that for us.
Neural Networks
Neuron

- neuron = activation function:
- linear
- binary step
- logistic
- tanh
- relu
- ...
AND gate

| \(x_1\) | 0 | 1 | 0 | 1 |
| \(x_2\) | 0 | 0 | 1 | 1 |
| AND | 0 | 0 | 0 | 1 |
- Hypothesis = logistic function:
\[h(x) = \frac{1}{1 + e^{-w^Tx}}\]
Intuition:
- \(w_0 \ll 0\)
- \(w_0 + w_1 \ll 0\)
- \(w_0 + w_2 \ll 0\)
- \(w_0 + w_1 + w_2 \gg 0\)
AND gate - learning
Non-linear problem: XOR gate

Neural network for XOR
x XOR y = (x AND NOT y) OR (y AND NOT x)

Hidden neuron #1:
0, 0 = 0.000555
0, 1 = 0.000001
1, 0 = 0.263002
1, 1 = 0.000827
Hidden neuron #2:
0, 0 = 0.000567
0, 1 = 0.290434
1, 0 = 0.000002
1, 1 = 0.001137
Final results:
0 XOR 0 = 0.035760
0 XOR 1 = 0.956746
1 XOR 0 = 0.956866
1 XOR 1 = 0.026566Tensorflow playground
Why do we need convolutional NN?
The more complicated problem is the more neurons we need
- so more CPU/GPU time
- and more memory

Convolutional Neural Networks
Idea

Convolution
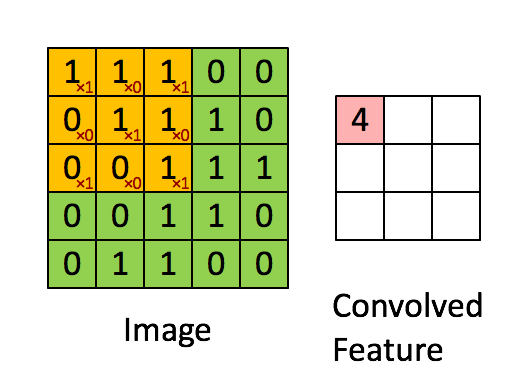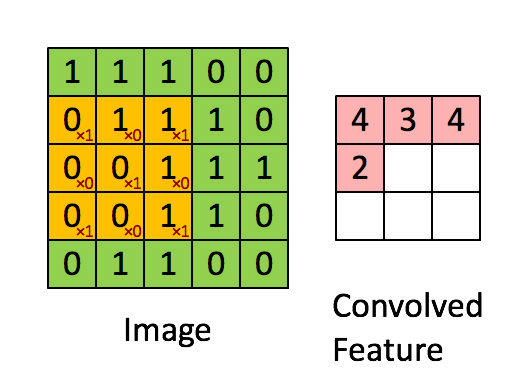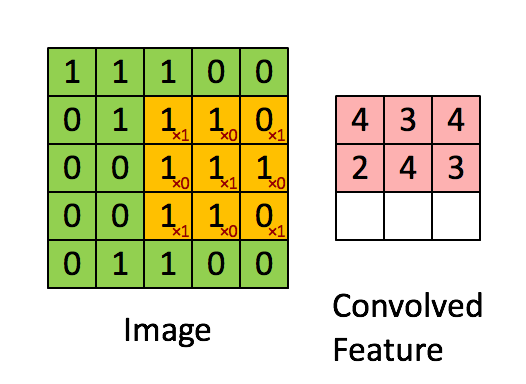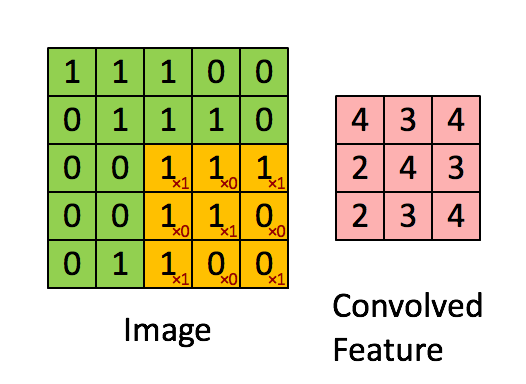
src: deeplearning.net
{kind=link}
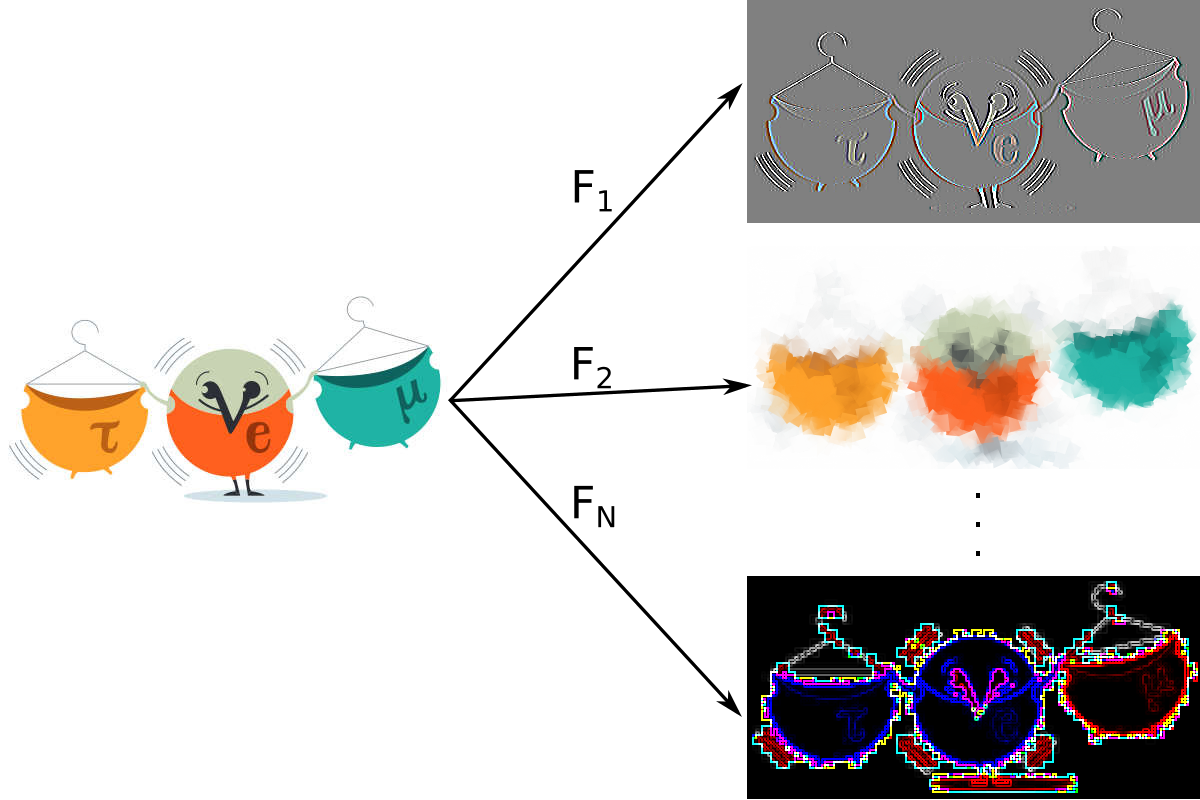
Convolution example
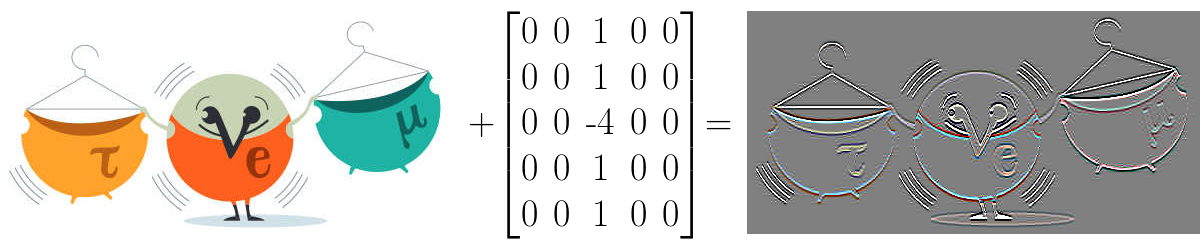
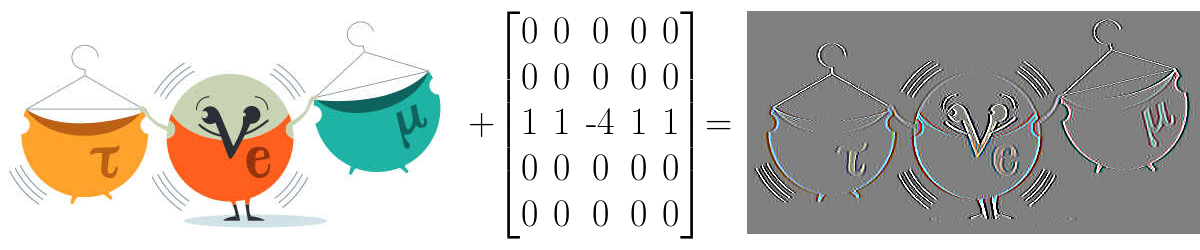
Convolution Layer
Pooling
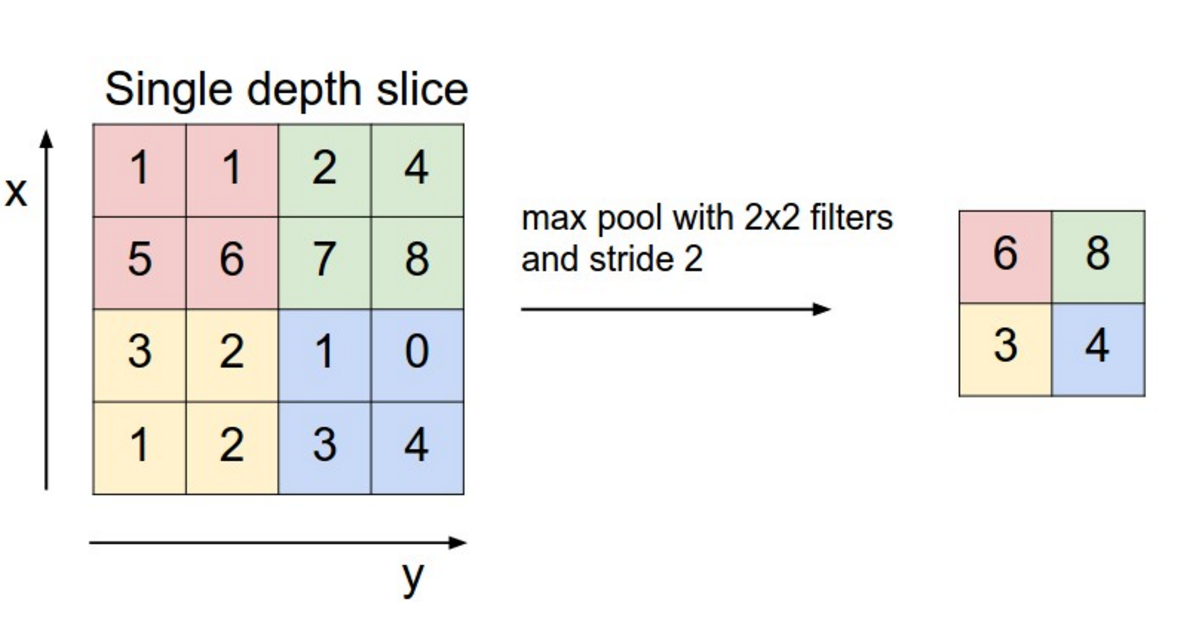
src: wildml.com
Pooling - example

src: arxiv
CNN example
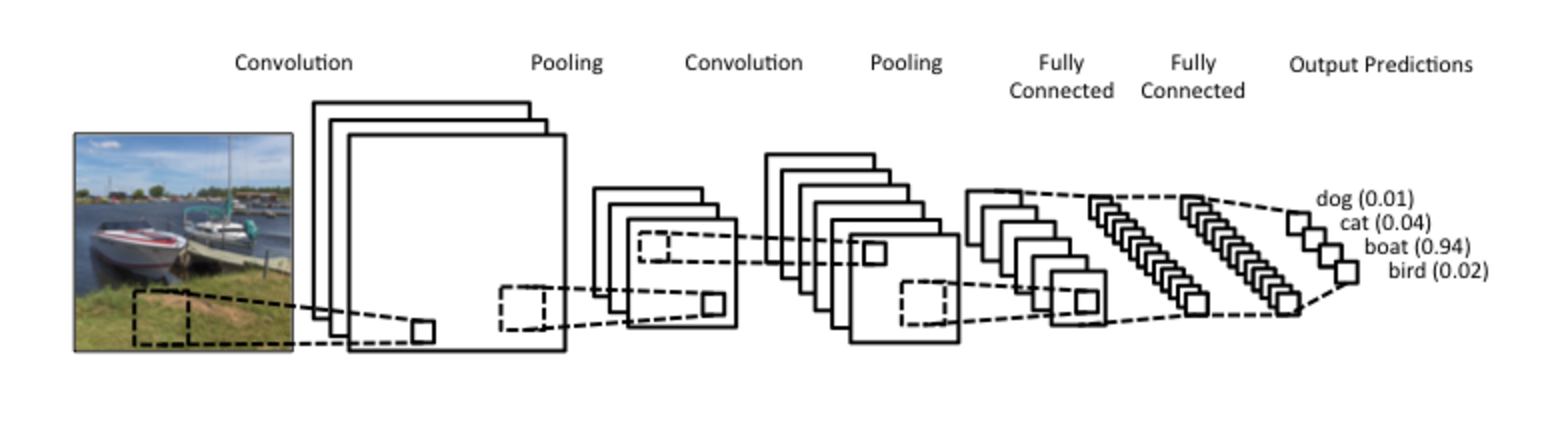
src: wildml.com
GoogLeNet



MLMPR
Machine Learning for MINERvA Physics Reconstruction
First task - vertex finding
the first goal is to use CNN to find the primary vertex in nuclear target region
each event is represented by 3 "pictures" - different views at the detector
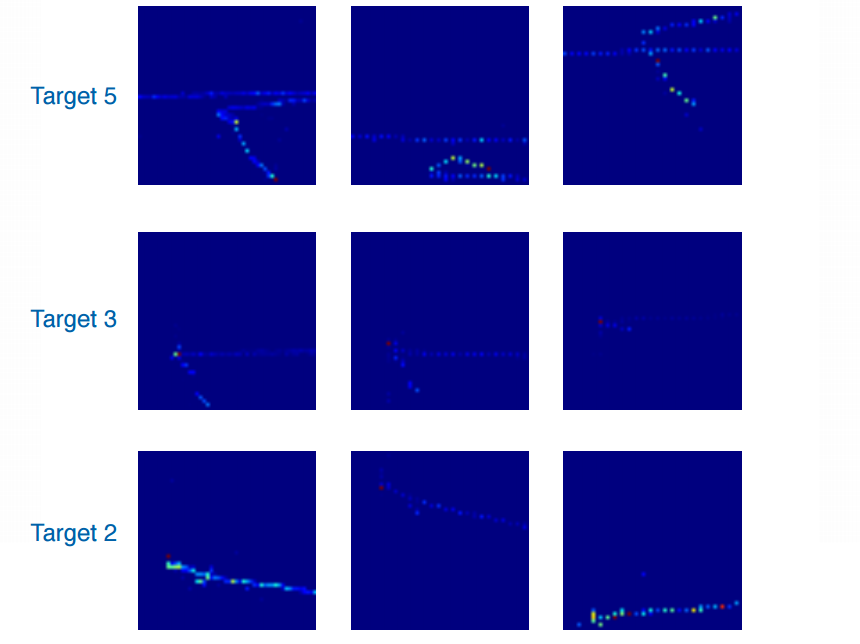 event examples courtesy of G. Perdue
event examples courtesy of G. Perdue
Classification regions
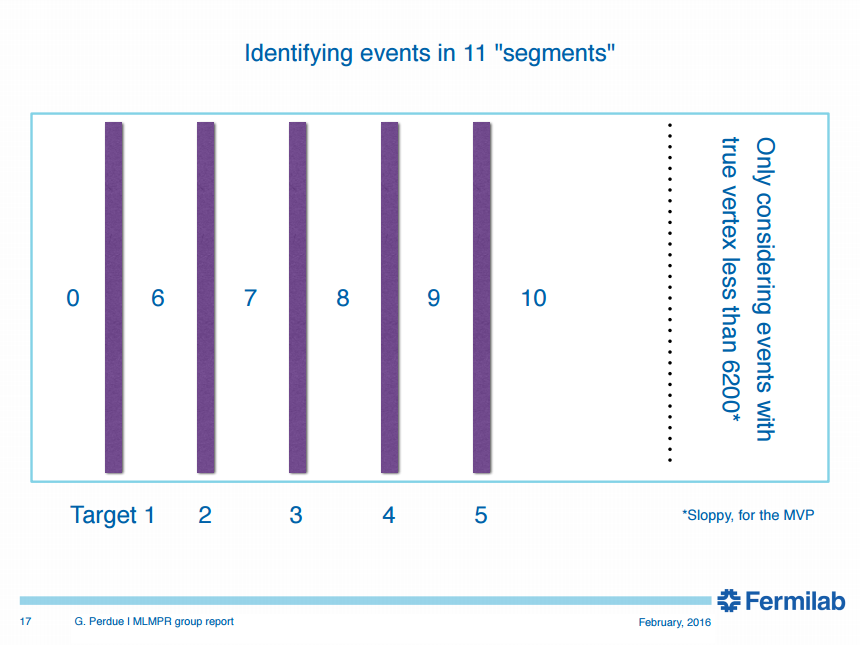
CNN in use
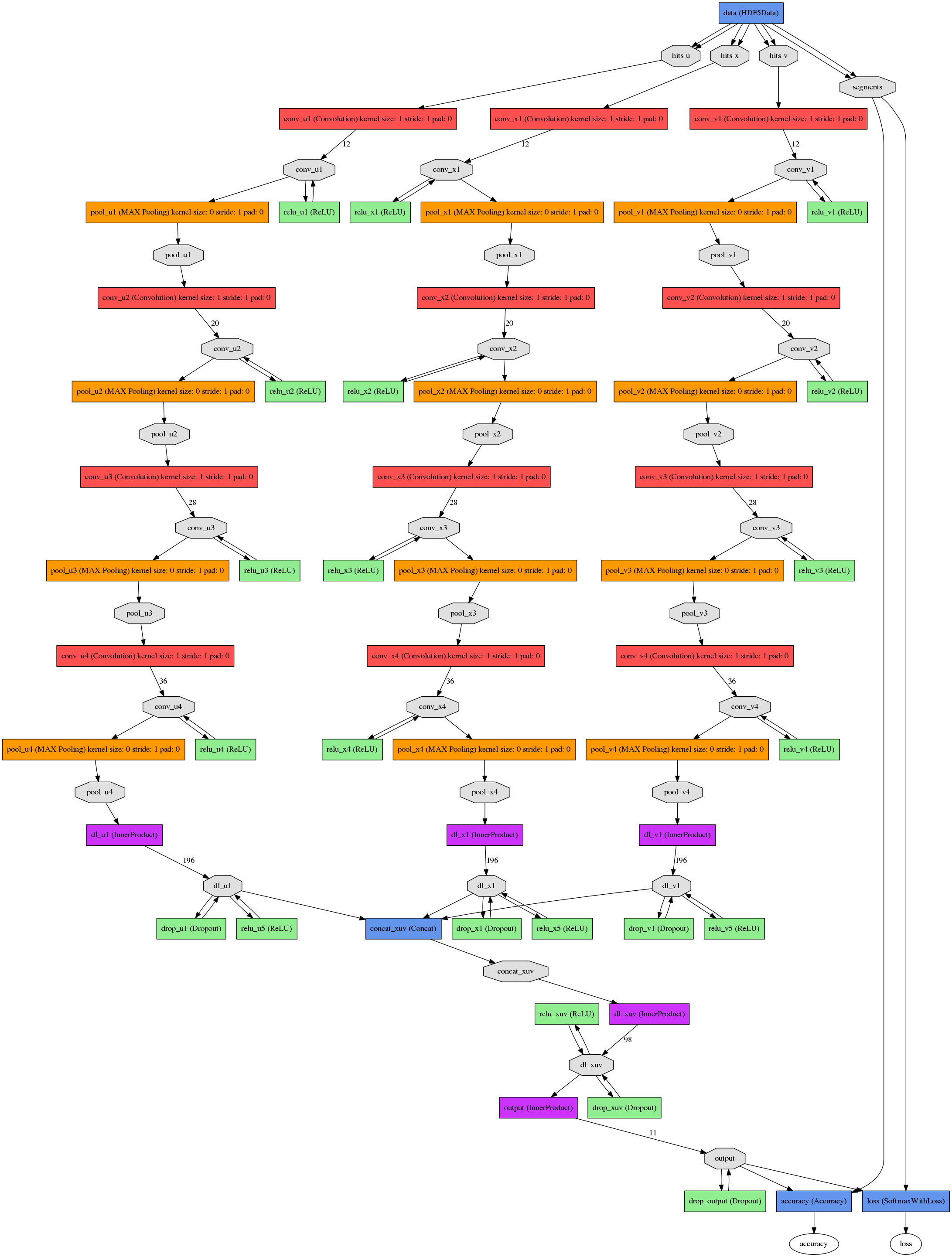
| Convolution layer | No. of filters | Filter size | Pool size |
| 1 | 12 | (8,3) | (2,1) |
| 2 | 20 | (7,3) | (2,1) |
| 3 | 28 | (6,3) | (2,1) |
| 4 | 36 | (6,3) | (2,1) |
and fully connected layers at the end
How did we get there?
In order to attain the impossible, one must attempt the absurd.
Miguel de Cervante
- Some educated guesses
- A little bit of intuition
- And many, many attempts
- ... on 2 GPU's
- ... and later using Titan
- Titan has 18,668 NVIDIA Kepler GPUs

What we got?
| Target | Track-based score [%] | CNN-based score [%] | Improvement [%] |
|---|---|---|---|
| 1 | 89.4 | 95.7 | 6.3 |
| 2 | 85.8 | 96.0 | 10.2 |
| 3 | 84.0 | 94.6 | 10.6 |
| 4 | 84.1 | 92.6 | 8.5 |
| 5 | 86.9 | 94.6 | 7.7 |
Summary
ML approach outperforms track-based reconstruction
It improves efficiency and purity
And this is just the beginning:
- hadron multiplicity?
- particle identification?
- energy/momentum reconstruction?
- ...
CNN would fail to access Physical Review database